
Max Ehrlich
I am a Research Scientist at NVIDIA
hardware engineering and an Adjunct Assistant Professor at the University of Maryland Computer Science
Department and UMIACS working in the
Perception and
Intelligence lab.
My current research combines machine learning and
computational
imaging to solve real problems. My focus is on breaking down and
understanding the first principles of the problem and then building
these principles back up into a machine learning solution rather than treating the model
as a black box.
In the past I have successfully applied this idea to image enhancement.
The broader
impact of this
is
to improve participation from underrepresented groups For example, by creating better
multimedia
compression algorithms which incorporate simple deep learning based techniques, people
operating in
underinvested locations (e.g., rural areas, native american reservations, 3rd world
countries) are able to participate in an increasingly media-focused internet.
I am grateful to have had recognition of the
importance of this work by many funding partners over
the years including government agencies: DARPA
and
IARPA, and private companies:
Facebook AI,
Adobe DIL,
and NVIDIA ADLR (where I currently
work).
I received my Ph.D. in Computer Science from the
University of Maryland
where
I was co-advised by Professor Larry
Davis
and
Professor Abhinav Shrivastava.
I received an M.S. in Computer Science from
Stevens
Institute of Technology. where I was advised by Professor Philippos Mordohai and a B.S. in
Computer Science
from Rutgers University.
I am a Member of
Association for the Advancement of Artificial
Intelligence (AAAI)
Institute of Electrical and Electronics Engineers
(IEEE)
Computer Vision Foundation
(CVF)
3/24 - I am co-organizing a CVPR 2024 workshop on Implicit Neural Representations for Vision,
please submit your papers!
2/24 - Our paper on explaning INRs, XINC, was
accepted to CVPR 2024.
1/24 - A preprint of our paper on explaning INRs, XINC, is now available on arXiv.
10/23 - Metabit, our algorithm
for generalized correction of compressed videos, was accepted to WACV 2024.
8/23 - Our paper on frequency
analysis of adversarial examples was accepted to BMVC 2023.
5/23 - Appointed as an Adjunct Assistant Professor at UMD.
2/23 - Our paper on neural compression
with implicit representations was accepted to CVPR 2023.
11/22 - Awarded the Larry S. Davis Doctoral Dissertation Award.
As an Adjunct member of the faculty I do not have funding to hire students, if you are interested in working with me please reach out to Professor Abhinav Shrivastava.
Service
Conference Reviewer: AAAI 2020, ICLR 2020, ECCV {2020-2022}, IJCAI 2021, CVPR {2021-2023}, ICML 2021, ICCV {2021-2023}, WACV {2022-2023}
Journal Reviewer: Transactions on Image Processing (TIP), International Journal of Artifical Intelligence (IJAI), The Visual Computer (TVCJ), Transactions on Circuits and Systems for Video Technology (TCSVT), IEEE Access, Digital Signal Processing
Contact
Contact me by email at
mehrlich {at} nvidia {dot} com
or stop by my office: IRB 4248
Students
- Shishira R Maiya (Ph.D. Student)
- Vatsal Agarwal (Ph.D. Student)
- Namitha Padmanabhan (Masters Student)
- Lillian Huang (M.S. Graduated Spring 2023)
- Evan Wen (High School Mentorship, currently undergrad UCLA)
Teaching
Spring 2024 CMSC421 Intro to Artificial Intelligence
Spring 2022 CMSC422 Intro to Machine Learning
My Research
My research emphasizes broad impact and collaboration with outside agencies. Aside from these research programs, I have participated in many other published research projects, please see my full list of papers and patents below for more information.Video Compression
Video sharing is increasingly popular and quickly becoming the primary method for interaction on the internet. With the globlal pandemic, video conferencing has become mandatory for many people to work or attend school. This causes major problems for people who lack a broadband connection. In this ongoing paper series on video compression, I am developing ways to incorporate deep learning models which run on commodity hardware and can be used in the near term. This research is conducted in collaboration with NVIDIA.

JPEG Compression
JPEG compression is the most popular image compression algorithm and currently powers image sharing on the internet and mobile phones. In this paper series on JPEG compression, I advanced theoretical knowledge about the interaction between JPEG compression and deep learning and used these theoretical results to improve the fidelity of JPEG images both for human and machine consumption. This research was primarly funded by a three year academic grant awarded to me by Facebook (Meta) AI, allowing me to work autonomously, and led to collaborations with Facebook.

Remote Sensing
In this program, we developed novel methods for improving land cover segmentation in sattelite images. This is a challenging and important problem with wide application from national defense to planning and surveying. This research was funded by the IARPA Core3D program.
Video Compression
Video sharing is increasingly popular and quickly becoming the primary method for interaction on the internet. With the globlal pandemic, video conferencing has become mandatory for many people to work or attend school. This causes major problems for people who lack a broadband connection. In this ongoing paper series on video compression, I am developing ways to incorporate deep learning models which run on commodity hardware and can be used in the near term. This research is conducted in collaboration with NVIDIA.
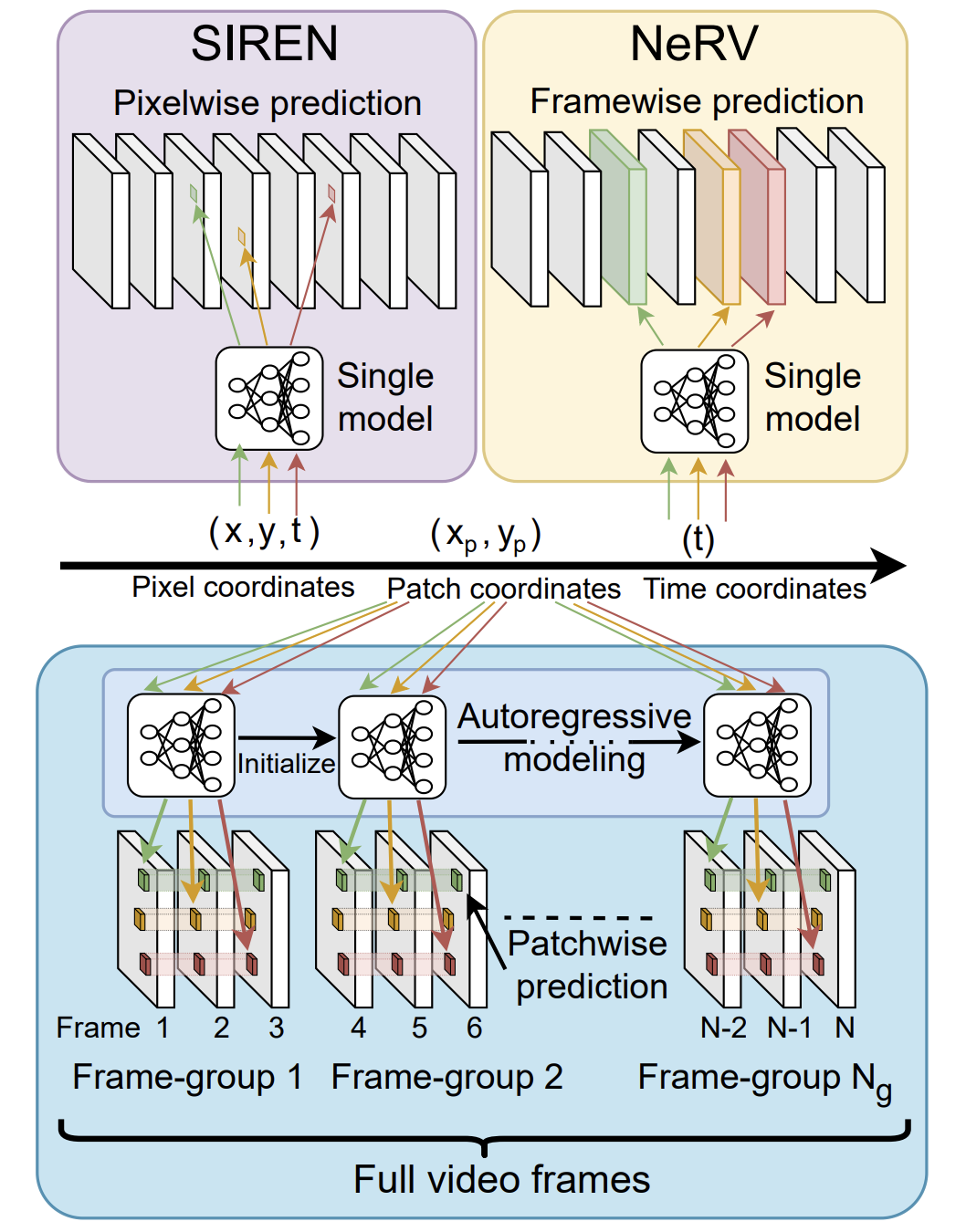
JPEG Compression
JPEG compression is the most popular image compression algorithm and currently powers image sharing on the internet and mobile phones. In this paper series on JPEG compression, I advanced theoretical knowledge about the interaction between JPEG compression and deep learning and used these theoretical results to improve the fidelity of JPEG images both for human and machine consumption. This research was primarly funded by a three year academic grant awarded to me by Facebook (Meta) AI, allowing me to work autonomously, and led to collaborations with Facebook.

- Prior works train an ensemble of models, one for each JPEG quality. We use a single network parameterized by the JPEG quantization matrix.
- Prior works deal with grayscale images only, with the assumption that their models can be applied channel-wise. We show that single-channel networks have trouble generalizing and design a network for color correction.
- Prior works focus on CNN regression which causes blurry and textureless results. We introduce a novel GAN loss that includes an explicit texture restoring term, this yields a more realistic result.

Remote Sensing
In this program, we developed novel methods for improving land cover segmentation in sattelite images. This is a challenging and important problem with wide application from national defense to planning and surveying. This research was funded by the IARPA Core3D program.

Full List of Papers and Patents
2024
Namitha Padmanabhan, Matthew Gwilliam, Pulkit Kumar, Shishira R Maiya, Max Ehrlich, Abhinav Shrivastava
In CVPR`
arXiv Cite It!
Max Ehrlich, Jon Barker, Namitha Padmanabhan, Larry S. Davis, Andrew Tao, Bryan Catanzaro, Abhinav Shrivastava
In WACV
arXiv Cite It!
2023
Shishira R. Maiya, Max Ehrlich, Vatsal Agarwal, Ser-Nam Lim, Tom Goldstein, Abhinav Shrivastava
In BMVC
arXiv Cite It!
Shishira R Maiya*, Sharath Girish*, Max Ehrlich, Hanyu Wang, Kwot Sin Lee, Patrick Poirson, Pengxiang Wu, Chen Wang, Abhinav Shrivastava
In CVPR
arXiv Cite It!
2022
Evan Wen, Rebecca Sorenson, Max Ehrlich
In ECCV Medical Computer Vision Workshop
arXiv Cite It!
Max Ehrlich
Doctoral Dissertation, University of Maryland College Park
arXiv Cite It!
2021
Max Ehrlich, Larry Davis, Ser-Nam Lim, Abhinav Shrivastava
In ICCV MELEX Workshop
arXiv CVF Cite It!
2020
Max Ehrlich, Larry Davis, Ser-Nam Lim, Abhinav Shrivastava
In ECCV
arXiv ECVA Cite It!
2019
Arthita Ghosh, Max Ehrlich, Larry Davis, Rama Chellappa
In IGARS
arXiv IEEE Cite It!
Max Ehrlich and Larry S. Davis
In ICCV
arXiv CVF Cite It!
Mohamed R. Amer, Timothy J. Shields, Amir Tamrakar, Max Ehrlich, Timur Almaev
U.S. Patent Application 16/085,859
Google Cite It!
2018
Arthita Ghosh, Max Ehrlich, Sohil Shah, Larry Davis, Rama Chellappa
In CVPR Workshops
CVF Cite It!
2017
Timothy J. Shields, Mohamed R. Amer, Max Ehrlich, Amir Tamrakar
In CVPR Workshops
CVF Cite It!
2016
Max Ehrlich and Philippos Mordohai
In 3DUI
IEEE Direct Cite It!
Max Ehrlich, Timothy J. Shields, Timur Almaev, Mohamed R. Amer
In CVPR Workshops
CVF Cite It!
2015
Max Ehrlich
Master's Thesis, Stevens Institute of Technology
Direct